
ZodiacXP
Erfahrenes Mitglied
Heute beginnt meine Recherche, wie man eine Multilinguale sprechende URL am besten umsetzt. Da beginnt es schon bei der Grundlage: Datenbank oder XML?
Datenbank mit NestedSet halte ich für schneller (auslesen, verschieben) als XML. Trifft das zu?
Wie löst man das Multilinguale dahinter? Es ist klar, dass es noch eine zweite Quelle mit Übersetzungen gibt und die zugehörigen Relationen, jedoch ist mir die Laufzeit enorm wichtig.
Hier kommt noch erschwerend hinzu: Verschiebt man in einer Sprache bei XML einen Knoten, so muss er in den anderen Dokumenten / Sprachen ebenfalls verschoeben werden, was mit einer Datenbank und Relationstabelle für die Übersetzung nicht der Fall wäre.
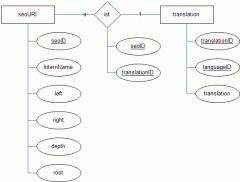
EDIT: Im Anhang ist eine Datenbankstruktur dafür. Das finde ich ziemlich komplex und aufwendig, jedes mal über drei Tabellen abzufragen und sie zu verbinden. Vor allem, da es bei jedem Klick und Besuch der Seite geschehen wird.
Wie macht man es richtig?
Datenbank mit NestedSet halte ich für schneller (auslesen, verschieben) als XML. Trifft das zu?
Wie löst man das Multilinguale dahinter? Es ist klar, dass es noch eine zweite Quelle mit Übersetzungen gibt und die zugehörigen Relationen, jedoch ist mir die Laufzeit enorm wichtig.
Hier kommt noch erschwerend hinzu: Verschiebt man in einer Sprache bei XML einen Knoten, so muss er in den anderen Dokumenten / Sprachen ebenfalls verschoeben werden, was mit einer Datenbank und Relationstabelle für die Übersetzung nicht der Fall wäre.
EDIT: Im Anhang ist eine Datenbankstruktur dafür. Das finde ich ziemlich komplex und aufwendig, jedes mal über drei Tabellen abzufragen und sie zu verbinden. Vor allem, da es bei jedem Klick und Besuch der Seite geschehen wird.
Wie macht man es richtig?
Anhänge
Zuletzt bearbeitet:
")