Promaetheus
Mitglied
Hallo liebe Forumskollegen!
Ich bin vor einiger Zeit auf Mac umgestiegen und erstelle nun auch mit diesem meine Skripte. Das Problem ist, dass die Umlaute nicht korrekt dargestellt werden. Um dieses Problem zu "umgehen", bzw. zu lösen habe ich schon folgende Aktionen durchgeführt:
eingefügt.
Trotz allem werden die Umlaute (zumindest in Safari und Firefox) falsch dargestellt. Anbei einige Screenshots. Ich bin am Ende meiner Weisheit und wäre Euch bezüglich Tipps hierzu SEHR dankbar.
Ich bin vor einiger Zeit auf Mac umgestiegen und erstelle nun auch mit diesem meine Skripte. Das Problem ist, dass die Umlaute nicht korrekt dargestellt werden. Um dieses Problem zu "umgehen", bzw. zu lösen habe ich schon folgende Aktionen durchgeführt:
- MySQL-Datenbank mit der Kollation "utf_8_general_ci" formatiert.
- Im Headerbereich der Seiten
Code:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />- Im Editor (Editra Version 0.7.08) die Dateiausgabe auf "utf-8" umgestellt.
Trotz allem werden die Umlaute (zumindest in Safari und Firefox) falsch dargestellt. Anbei einige Screenshots. Ich bin am Ende meiner Weisheit und wäre Euch bezüglich Tipps hierzu SEHR dankbar.
Anhänge
-
 Bildschirmfoto 2012-07-29 um 11.00.31.png7,5 KB · Aufrufe: 12
Bildschirmfoto 2012-07-29 um 11.00.31.png7,5 KB · Aufrufe: 12 -
 Bildschirmfoto 2012-07-29 um 11.01.12.png7,9 KB · Aufrufe: 15
Bildschirmfoto 2012-07-29 um 11.01.12.png7,9 KB · Aufrufe: 15 -
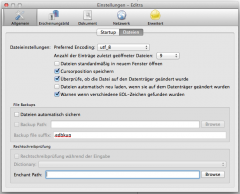 Bildschirmfoto 2012-07-29 um 11.01.26.png70,1 KB · Aufrufe: 24
Bildschirmfoto 2012-07-29 um 11.01.26.png70,1 KB · Aufrufe: 24 -
 Bildschirmfoto 2012-07-29 um 11.01.47.png16,1 KB · Aufrufe: 14
Bildschirmfoto 2012-07-29 um 11.01.47.png16,1 KB · Aufrufe: 14 -
 Bildschirmfoto 2012-07-29 um 11.03.02.png7,6 KB · Aufrufe: 10
Bildschirmfoto 2012-07-29 um 11.03.02.png7,6 KB · Aufrufe: 10