flowerpower hat gesagt.:
Könntest Du für einen Newbie noch mal die Merge-Funkton aus einander nehmen, habe heute schon den ganzen Tag hier dran gesessen.
Aber klar, also hier MERGE im einzelnen.
Also MERGE macht im Grunde folgendes:
1.) Ich gebe dem MERGE Statement eine Menge an Daten
SQL:
USING ( SELECT s_word AS word FROM DUAL ) f
In unserem Fall ist es einfach nur das eine Wort aus dem Satz,könnte aber z.B. auch ein Select aus einer Tabelle sein...
2.) Ich sage dem Statement in welcher Tabelle ich meine Daten haben möchte
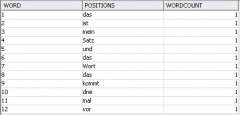
3.) Ich definiere woran MERGE erkennt, ob es den Satz schon gibt oder nicht, also im Normalfall meinen Primary Key
Bei uns ist es das gefundene Wort im Satz und die Spalte mit den Wörtern in der Tabelle
4.) Ich beschreibe was MERGE machen soll, falls es den Eintrag schon gibt
SQL:
WHEN MATCHED THEN UPDATE SET
positions = positions || ' ' || TO_CHAR( i ),
wordcount = wordcount + 1
Wir hängen die Position des Wortes an den vorhandenen String an und zählen die Wortanzahl um eins hoch
5.) Ich beschreibe was MERGE machen soll wenn das Wort nicht gefunden wird
SQL:
WHEN NOT MATCHED THEN INSERT (word, positions, wordcount ) VALUES ( s_word, TO_CHAR( i ), 1 );
Klar, ein einfaches INSERT Statement
Somit macht das MERGE Statement also das Prüfen, "Ist es schon da?, dann UPDATE, sonst INSERT" überflüssig und vor allem schneller, da ich nicht jeden Satz prüfen muss, sondern auch eine ganze Datenmenge "mergen" kann.
Ich hab das Beispiel übrigens nochmal getestet und bei mir gehts einwandfrei. Ich kann mir jetzt nur noch vorstellen, dass entweder deine Tabellenspalten anders rum definiert sind als bei mir ? (DESC)
oder dass es tatsächlich Unterschiede wegen der Version gibt, wobei mir dann das Verhalten unter 9.2.0.1 nicht ganz klar wäre...?

")