Guten Abend ") ,
,
ich habe ein kleines Problem und trotz intensiver Suche und probierens finde ich keine Lösung daher hoffe ich auf eure hilfe:
Ich bin dabei ein tool zu schreiben was einen link bekommt und dann die daten der website als String
einliest. Das klappt alles auch soweit ganz gut.
Jetzt ist es aber so dass mehrere Seiten (links) direkt hintereinander in einer schleife eingelesen werden müssen und genau DA ist das Problem.
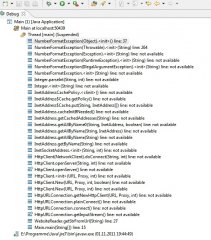
Lass ich nur einen Link einlesen klappt alles wie es soll. Lass ich zwei links einlesen macht er mit dem ersten was er soll und dann steht das Programm....entweder dauert es seeeeehr lange oder es tut sich nichts mehr (was es genau ist kann ich leider nicht sagen) .
.
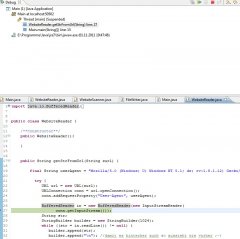
Das ist der CodeAusschnitt
Wenn ich den unteren Teil, also die schleife nur bis 1 laufen lasse klappt alles super, sobald er das für mehrere nacheinander machen soll ist es vorbei und ersteht ...
Woran kann das liegen? Zwar sind es jeweils immer mehr als 120.000 Zeilen aber der Speicher kann ja wohl kaum voll sein oder?
Was kann ich machen?
Sorry, ich hoffe ich konnte mich verständlich genug ausdrücken ^^...
Ich hoffe sehr auf eure Hilfe.
vielen Dank im voraus
,ich habe ein kleines Problem und trotz intensiver Suche und probierens finde ich keine Lösung daher hoffe ich auf eure hilfe:
Ich bin dabei ein tool zu schreiben was einen link bekommt und dann die daten der website als String
einliest. Das klappt alles auch soweit ganz gut.
Jetzt ist es aber so dass mehrere Seiten (links) direkt hintereinander in einer schleife eingelesen werden müssen und genau DA ist das Problem.
Lass ich nur einen Link einlesen klappt alles wie es soll. Lass ich zwei links einlesen macht er mit dem ersten was er soll und dann steht das Programm....entweder dauert es seeeeehr lange oder es tut sich nichts mehr (was es genau ist kann ich leider nicht sagen)
. Das ist der CodeAusschnitt
Java:
/**Scanning First SensorSites to get HTML Format**/
WebsiteScanner sensorScanner = new WebsiteScanner(htmlCodeSensor, linkAfterString);
//anzahl der links
arrayLength = sensorScanner.getHtmlFormat().length;
String[] htmlSensorLinks = new String[arrayLength];
for(int i=0; i < arrayLength ; i++){
//holt sich von einer anderen Seite die links die er durchsuchen soll
htmlSensorLinks[i] = sensorScanner.getHtmlFormat()[i];
}
/**Scanning SensorSites with Data**/
//startet die instanz des Readers der die Methode enthält die den html code einliest
WebsiteReader dataSite = new WebsiteReader();
//String Array welches die html Codes die eingelesen wurden aufnehmen soll
String[] htmlCodeDataSite = new String[arrayLength];
//durchläuft die anzahl der vorhandenen links die eingelesen werden sollen
for(int i=0; i < arrayLength; i++){
//liest die seiten hinter den links ein
htmlCodeDataSite[i] = dataSite.getStrFromUrl(htmlSensorLinks[i]);
//durchsucht den html code nach den wichtigen daten...
WebsiteScanner sensorDataScanner = new WebsiteScanner(htmlCodeDataSite[i], dataStartTag, dataEndTag, timeStartTag, timeEndTag);
//...und erzeugt eine arrayList mit den wichtigen daten in dieser Methode
sensorDataScanner.scanForSensorData();
}Wenn ich den unteren Teil, also die schleife nur bis 1 laufen lasse klappt alles super, sobald er das für mehrere nacheinander machen soll ist es vorbei und ersteht ...
Woran kann das liegen? Zwar sind es jeweils immer mehr als 120.000 Zeilen aber der Speicher kann ja wohl kaum voll sein oder?
Was kann ich machen?
Sorry, ich hoffe ich konnte mich verständlich genug ausdrücken ^^...
Ich hoffe sehr auf eure Hilfe.
vielen Dank im voraus