Hallo, ich bin relativ neu hier und noch nicht so fit in C. Ich bin auf ein Problem gestoßen, wobei mir bisher keiner weiterhelfen konnte. Ich hab auch gesehen, das ziemlich viel zu finden ist über Datei auslesen usw., aber wirklich weitergeholfen hat es mir nicht.
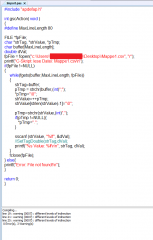
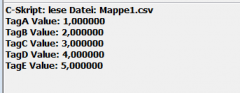
Zu meinem Problem: Ich muss in ANS C aus einer CSV Datei Werte lesen. Ich kenn jetzt den unterschied zwischen ANS C und "normal" C nicht wirklich. Ich hab auch schon ein Beispielprogramm bekommen und auch ausprobiert aber irgendwie funktioniert das ganze nicht richtig.
Dazu sei noch gesagt, das ganze wird in einem Programm von Siemens (WinCC V7.3) verarbeitet, deswegen auch ANS C. Und das Programmbeispiel ist auch von Siemens.
Ich bekomm meine gewünschte Datei geöffnet, nur wenn ich versuche irgendwas raus zu lesen, bekomm ich folgenden Fehler: general protection fault (Fehlermeldung vom WinCC). Der Compiler übersetzt alles wunderbar nur mit 3 Warnungen (Anhang).
Ich hoffe ihr könnt mir helfen... Vielen Dank schon einmal im vorraus
Zu meinem Problem: Ich muss in ANS C aus einer CSV Datei Werte lesen. Ich kenn jetzt den unterschied zwischen ANS C und "normal" C nicht wirklich. Ich hab auch schon ein Beispielprogramm bekommen und auch ausprobiert aber irgendwie funktioniert das ganze nicht richtig.
Dazu sei noch gesagt, das ganze wird in einem Programm von Siemens (WinCC V7.3) verarbeitet, deswegen auch ANS C. Und das Programmbeispiel ist auch von Siemens.
Ich bekomm meine gewünschte Datei geöffnet, nur wenn ich versuche irgendwas raus zu lesen, bekomm ich folgenden Fehler: general protection fault (Fehlermeldung vom WinCC). Der Compiler übersetzt alles wunderbar nur mit 3 Warnungen (Anhang).
Ich hoffe ihr könnt mir helfen... Vielen Dank schon einmal im vorraus