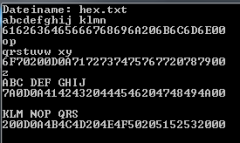
Ich habe versucht die oben genannte Aufgabe zu lösen. Allerdings werden keine 16 Buchstaben in einer Zeile ausgegeben (Siehe Bild).
Außerdem wird nicht der Rest ausgegeben aber ich weiß auch warum das so ist. Wenn ich noch den Rest mplementiere, dann habe ich insgesamt 4 Schleifen.
Es gibt bestimmt eine bessere Lösung?
Außerdem wird nicht der Rest ausgegeben aber ich weiß auch warum das so ist. Wenn ich noch den Rest mplementiere, dann habe ich insgesamt 4 Schleifen.
Es gibt bestimmt eine bessere Lösung?
abcdefghij klmnop
qrstuvw xyz
ABC DEF GHIJ
KLM NOP QRS TUVW
XY
Z
qrstuvw xyz
ABC DEF GHIJ
KLM NOP QRS TUVW
XY
Z
C++:
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
using namespace std;
int main() {
string dateiname = "";
char c = ' ';
const string codierung{ "0123456789ABCDEF" };
int ctr = 0;
vector<int> v(16);
vector<string> zeichen(16);
cout << "Dateiname: ";
cin >> dateiname;
ifstream quelle( dateiname, ios::binary );
while (quelle.get(c)) {
zeichen.at(ctr) = c;
v.at(ctr)= static_cast<int> (c);
ctr++;
if (ctr == 15) {
for (int i = 0; i < 16; i++) {
cout << zeichen.at(i);
}
cout << "\n";
for (int i = 0; i < 16;i++) {
cout << codierung.at(v.at(i)/16) << codierung.at(v.at(i)%16);
}
cout << "\n";
ctr = 0;
}
}
cout << "\n";
getchar();
quelle.close();
getchar();
return 0;
}
") GiB Arbeitsspeicher, während es in 4 GB Arbeitsspeicher möglich wäre. Wie viel Arbeitsspeicher hast du zur Verfügung? Wie viel Arbeitsspeicher hat ein Durchschnittscomputer?
GiB Arbeitsspeicher, während es in 4 GB Arbeitsspeicher möglich wäre. Wie viel Arbeitsspeicher hast du zur Verfügung? Wie viel Arbeitsspeicher hat ein Durchschnittscomputer?