micha
Erfahrenes Mitglied
Liebe Community,
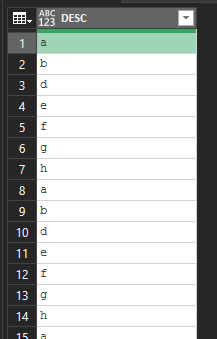
ich habe eine Protokolldatei mit Tausenden von Textzeilen, die als Debug von einem Programm gesendet werden und jeden Schritt auflistet, der ausgeführt wurde.
Um das Programm zu optimieren, analysiere ich das Protokoll mit Hilfe von Power Query und zähle die Anzahl der Zeilen mit einem bestimmten Inhalt (z. B. "06:56:12 - Start von Aktivität A" oder eine andere Zeile "07:51:12 - Ende fehlgeschlagen"), um die Anzahl der Vorkommnisse für jedes Ereignis zu ermitteln.
Eines dieser Ereignisse "Ende fehlgeschlagen" hat eine zusätzliche Anforderung, die ich mit der Power Query noch nicht erfüllen kann:
- Das Ereignis "Ende fehlgeschlagen" kommt in der Protokolldatei mehrfach vor,
- Um den Grund für "Ende fehlgeschlagen" zu analysieren, muss ich die letzten 20 Zeilen oberhalb des Ereignisses überprüfen
Mein bisheriger Ansatz: Ich habe zwei neue Spalten erstellt:
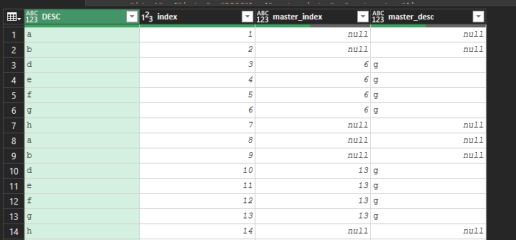
- eine Bedingungsspalte, die prüft, ob die ursprüngliche Spalte den Wortlaut "Ende fehlgeschlagen" enthält. Wenn die Bedingung erfüllt ist, gebe ich "ja" aus, sonst "nein".
- eine Indexspalte, die es mir ermöglicht, nach der Filterung der vorherigen bedingten Spalte auf "ja" jede Zeile zu identifizieren, die den Inhalt "Ende fehlgeschlagen" hat.
Meine Idee war, diese Tabelle für den nächsten Schritt zu verwenden:
- Für jede Zeile in dieser Tabelle möchte ich die Zeilen index-1 bis index-20 oberhalb der entsprechenden Indexzeile hinzufügen.
Eine Sortierung nach Index würde mir dann die Abfolge der Ereignisse in der Protokolldatei liefern, allerdings nur gefiltert nach "Ende fehlgeschlagen" und den entsprechenden 20 Zeilen darüber.
- Mit dieser Ausgabe kann ich dann die gesamte Spalte in einer Pivot-Tabelle analysieren, welche Ereignisse wie oft vor "Ende fehlgeschlagen" in der gesamten Protokolldatei aufgetreten sind.
Wie würdet Ihr die Situation angehen?
Vielen Dank für die Hilfe!
ich habe eine Protokolldatei mit Tausenden von Textzeilen, die als Debug von einem Programm gesendet werden und jeden Schritt auflistet, der ausgeführt wurde.
Um das Programm zu optimieren, analysiere ich das Protokoll mit Hilfe von Power Query und zähle die Anzahl der Zeilen mit einem bestimmten Inhalt (z. B. "06:56:12 - Start von Aktivität A" oder eine andere Zeile "07:51:12 - Ende fehlgeschlagen"), um die Anzahl der Vorkommnisse für jedes Ereignis zu ermitteln.
Eines dieser Ereignisse "Ende fehlgeschlagen" hat eine zusätzliche Anforderung, die ich mit der Power Query noch nicht erfüllen kann:
- Das Ereignis "Ende fehlgeschlagen" kommt in der Protokolldatei mehrfach vor,
- Um den Grund für "Ende fehlgeschlagen" zu analysieren, muss ich die letzten 20 Zeilen oberhalb des Ereignisses überprüfen
Mein bisheriger Ansatz: Ich habe zwei neue Spalten erstellt:
- eine Bedingungsspalte, die prüft, ob die ursprüngliche Spalte den Wortlaut "Ende fehlgeschlagen" enthält. Wenn die Bedingung erfüllt ist, gebe ich "ja" aus, sonst "nein".
- eine Indexspalte, die es mir ermöglicht, nach der Filterung der vorherigen bedingten Spalte auf "ja" jede Zeile zu identifizieren, die den Inhalt "Ende fehlgeschlagen" hat.
Meine Idee war, diese Tabelle für den nächsten Schritt zu verwenden:
- Für jede Zeile in dieser Tabelle möchte ich die Zeilen index-1 bis index-20 oberhalb der entsprechenden Indexzeile hinzufügen.
Eine Sortierung nach Index würde mir dann die Abfolge der Ereignisse in der Protokolldatei liefern, allerdings nur gefiltert nach "Ende fehlgeschlagen" und den entsprechenden 20 Zeilen darüber.
- Mit dieser Ausgabe kann ich dann die gesamte Spalte in einer Pivot-Tabelle analysieren, welche Ereignisse wie oft vor "Ende fehlgeschlagen" in der gesamten Protokolldatei aufgetreten sind.
Wie würdet Ihr die Situation angehen?
Vielen Dank für die Hilfe!