Hallo zusammen,
ich habe eine Frage zu dem folgend Statement:
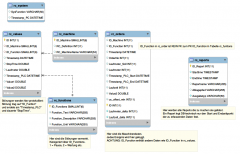
Die Abfrage auf der lokalen DB braucht ewig (127 Sekunden) und ich würde gerne wissen, ob man diese optimieren kann.
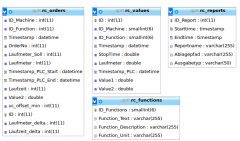
Die Tabelle rc_values hat ~230.000 Werte.
Gruß
domeemod
ich habe eine Frage zu dem folgend Statement:
SQL:
SELECT
SELECT
rc_orders.Timestamp_PLC_Start AS Datum_start,
rc_orders.ID_Function,
sum(rc_values.Stoptime),
count(*)
FROM rc_orders, rc_reports, rc_values, rc_functions
WHERE rc_orders.Timestamp_PLC_End between rc_reports.Starttime and rc_reports.Endtime
and rc_orders.ID_Machine = 3
and (rc_values.Timestamp_PLC between rc_orders.Timestamp_PLC_start and rc_orders.Timestamp_PLC_End)
group by DATE(rc_orders.Timestamp_PLC_End)Die Abfrage auf der lokalen DB braucht ewig (127 Sekunden) und ich würde gerne wissen, ob man diese optimieren kann.
Die Tabelle rc_values hat ~230.000 Werte.
Gruß
domeemod