Sparks
Mitglied
Hallo,
(wenn das hier falsch eingetragen ist, bitte verschieben, danke!)
Es geht um eine Anwendung, die mit einer Übersetzung auch für Multibyte-Sprachen (z. B. japanisch) läuft. Die Texte (Labels usw.) werden aus einer Datenbank-Tabelle ausgelesen (da könnte man drüber diskutieren, ob das der beste Weg ist, das lässt sich jetzt aber nicht ändern!)
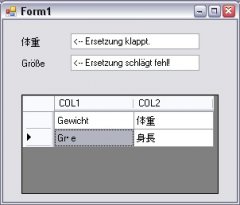
Leider bekomme ich aber die deutschen Umlaute und Sonderzeichen (wie ß) nicht genau so wie den ursprünglichen Unicode string zurück.
Zur Veranschaulichung des Problems habe ich einen kleinen Screenshot beigefügt.
Wie kann ich dieses Beispiel "Gr·e" statt "Größe" umsetzen?
Die Win-API-Funktion MulitByteToWideChar (in Kernel32.dll) hat mir nicht geholfen, bzw. ich bekomme eine StackOverflow-Exception: "An unhandled exception of type 'System.StackOverflowException' occurred in mscorlib.dll" beim zweiten Aufruf (Zeile 8.):
Oder gibt es eine andere Möglichkeit, z. B. mit den System.Text.Encoding-Klassen?
Ich habe an der Stelle gar keine Erfahrungen.
Danke und Gruß,
Sparks
(wenn das hier falsch eingetragen ist, bitte verschieben, danke!)
Es geht um eine Anwendung, die mit einer Übersetzung auch für Multibyte-Sprachen (z. B. japanisch) läuft. Die Texte (Labels usw.) werden aus einer Datenbank-Tabelle ausgelesen (da könnte man drüber diskutieren, ob das der beste Weg ist, das lässt sich jetzt aber nicht ändern!)
Leider bekomme ich aber die deutschen Umlaute und Sonderzeichen (wie ß) nicht genau so wie den ursprünglichen Unicode string zurück.
Zur Veranschaulichung des Problems habe ich einen kleinen Screenshot beigefügt.
Wie kann ich dieses Beispiel "Gr·e" statt "Größe" umsetzen?
Die Win-API-Funktion MulitByteToWideChar (in Kernel32.dll) hat mir nicht geholfen, bzw. ich bekomme eine StackOverflow-Exception: "An unhandled exception of type 'System.StackOverflowException' occurred in mscorlib.dll" beim zweiten Aufruf (Zeile 8.):
C#:
try
{
// sOriginal enthält den Double-Byte-String
int nSizeUnicode = MultiByteToWideChar(0, 0, sOrginal, -1, ref cUnicode, 0);
if (nSizeUnicode > 0)
{
cUnicode = new char[nSizeUnicode];
MultiByteToWideChar(0, 0, sOrginal, -1, ref cUnicode, nSizeUnicode);
sRueckgabe = cUnicode.ToString();
}
}
catch (Exception e)
{
throw;
}Ich habe an der Stelle gar keine Erfahrungen.
Danke und Gruß,
Sparks
") ).
).