versuch13
Erfahrenes Mitglied
Ich habe zwei Tabellen
nodes
id | date | title | url | content
comments
id | nid | date | content
und möchte nun Abfragen, zu welchen Themen zuletzt Kommentare verfasst wurden.
Jetzt könnte man einfach nur die letzten Reihen der comments Tabelle abfragen,
aber das möchte ich nicht aus dem Grund falls z.B. mehrere Ergebnisreihen sich
auf eine Reihe der Tabelle nodes beziehen.
So, daher dachte ich mir, ich gruppiere die Ergebnismenge anhand des Feldes url
der Tabelle nodes da diese einmalig sind oder anhand des Feldes nid in comments.
So bekomme ich auch zu jeder node nur ein Ergebnis, allerdings nicht in der korrekten Reihenfolge. ORDER BY liefert nicht das letzte Datum sondern das erste.
Verständlich was ich meine? Gibt es eine Lösung? Danke schon mal.
nodes
id | date | title | url | content
comments
id | nid | date | content
und möchte nun Abfragen, zu welchen Themen zuletzt Kommentare verfasst wurden.
Jetzt könnte man einfach nur die letzten Reihen der comments Tabelle abfragen,
aber das möchte ich nicht aus dem Grund falls z.B. mehrere Ergebnisreihen sich
auf eine Reihe der Tabelle nodes beziehen.
So, daher dachte ich mir, ich gruppiere die Ergebnismenge anhand des Feldes url
der Tabelle nodes da diese einmalig sind oder anhand des Feldes nid in comments.
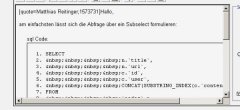
Code:
SELECT
one.`id`,
one.`user`,
two.`title`,
two.`url`,
CONCAT(SUBSTRING_INDEX(one.content, ' ', 3), ' …') as `content`
FROM
`comments` as one
INNER JOIN
`nodes` as two
ON
one.`nid` = two.`id`
GROUP BY
two.`url`
ORDER BY
one.date DESC
LIMIT 6So bekomme ich auch zu jeder node nur ein Ergebnis, allerdings nicht in der korrekten Reihenfolge. ORDER BY liefert nicht das letzte Datum sondern das erste.
Verständlich was ich meine? Gibt es eine Lösung? Danke schon mal.
")
")