cocoon
Erfahrenes Mitglied
Hallo,
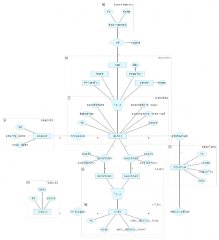
ich habe eine Frage zu der is-a-Beziehung (Generalisierung/Spezialisierung/Vererbung) in einem ER-Modell, nämlich wie ich diese letztlich in einem Datenbanksystem (hier: mySQL) umsetze. Über die Suche habe ich zu entsprechenden Begriffen leider nichts gefunden. Zum besseren Verständnis habe ich einen Ausschnitt des ERMs angehangen.
Über google habe ich gefunden, dass eine is-a-Beziehung wie folgt abgebildet wird:
Die vererbende Entität wird samt ihrer Attribute in einer eigenen Tabelle umgesetzt. Ebenso werden alle erbenden Entitäten in eigenen Tabellen umgesetzt und erhalten (neben den sie spezialisierenden Attributen) als ID den Schlüssel der vererbenden Tabelle.
Auf mein Beispiel bezogen wirft das folgende Fragen auf:
- Wie sieht es aus, wenn eine Entität zwar sinngemäß spezialisiert ist, aber keine weiteren Attribute erhält, die sie von der vererbenden Entität abhebt? In Beispiel: Ein Freundschaftsspiel (friendly) ist ein Spiel (match), ebenso ist es ein Testspiel (test). Sie unterscheiden sich aber durch keine Attribute davon. Macht es Sinn, jetzt Tabellen umzusetzen, die nur eine ID haben?!
- Die Spezialisierung "Verein (club) ist ein Heim/Auswärts-Team (hometeam/awayteam)" und die damit verbundene Beziehung zum Spiel (match) habe ich mit in die Tabelle "match" umgesetzt: so erhält ein "match" zwei Fremdschlüssel von den (Heim/Auswärts)Clubs und ferner die Tore und Halbzeit-Tore. Ist das richtig umgesetzt?!
Okay, ist mal wieder viel Text, hoffe trotzdem, Ihr könnt mir helfen.") Danke schonmal!
Danke schonmal!
ich habe eine Frage zu der is-a-Beziehung (Generalisierung/Spezialisierung/Vererbung) in einem ER-Modell, nämlich wie ich diese letztlich in einem Datenbanksystem (hier: mySQL) umsetze. Über die Suche habe ich zu entsprechenden Begriffen leider nichts gefunden. Zum besseren Verständnis habe ich einen Ausschnitt des ERMs angehangen.
Über google habe ich gefunden, dass eine is-a-Beziehung wie folgt abgebildet wird:
Die vererbende Entität wird samt ihrer Attribute in einer eigenen Tabelle umgesetzt. Ebenso werden alle erbenden Entitäten in eigenen Tabellen umgesetzt und erhalten (neben den sie spezialisierenden Attributen) als ID den Schlüssel der vererbenden Tabelle.
Auf mein Beispiel bezogen wirft das folgende Fragen auf:
- Wie sieht es aus, wenn eine Entität zwar sinngemäß spezialisiert ist, aber keine weiteren Attribute erhält, die sie von der vererbenden Entität abhebt? In Beispiel: Ein Freundschaftsspiel (friendly) ist ein Spiel (match), ebenso ist es ein Testspiel (test). Sie unterscheiden sich aber durch keine Attribute davon. Macht es Sinn, jetzt Tabellen umzusetzen, die nur eine ID haben?!
- Die Spezialisierung "Verein (club) ist ein Heim/Auswärts-Team (hometeam/awayteam)" und die damit verbundene Beziehung zum Spiel (match) habe ich mit in die Tabelle "match" umgesetzt: so erhält ein "match" zwei Fremdschlüssel von den (Heim/Auswärts)Clubs und ferner die Tore und Halbzeit-Tore. Ist das richtig umgesetzt?!
Okay, ist mal wieder viel Text, hoffe trotzdem, Ihr könnt mir helfen.
Danke schonmal!